多重基因片段:实现更佳高通量筛选的关键

多重基因片段:实现更佳高通量筛选的关键
Twist现提供301至500bp的混合双链DNA(dsDNA)合成服务 图像展示了从黑暗中螺旋而出的双链DNA螺旋的图形渲染。
当一个实验还只是一个想法时,其实践上的限制很容易被发现的诱人潜力所掩盖。很难意识到实验室工作中不完美的现实如何积累起来,尤其是当看似合理地只需再增加几个样本、几个变量,或许再添加一两个步骤时。但当到了装载吸管并启动实验的时刻,真相变得清晰:做更少的事常常是实现更多的最佳方式。
在高通量筛选的背景下尤其如此,研究人员必须经常经历从较小的合成寡核苷酸组装长段双链DNA(dsDNA)的繁琐过程。概念上,这个过程很简单:合成成千上万到几十万所需的寡核苷酸,将这些转换成dsDNA格式,克隆到载体中,并传递到目标细胞进行表达和下游筛选。这是许多高通量应用的基础,从大规模并行报告基因分析(MPRA)到大规模抗体开发项目。尽管高通量筛选的想法简单,但实际执行却远非如此。
研究人员在这些项目中面临的一个微妙而重要的障碍是需要混合DNA片段的合成。通过常规方法可以构建单个dsDNA片段,但这些技术不易扩展。当需要成千上万个不同的dsDNA片段时,如在高通量筛选中,研究人员必须依靠极为有限的混合dsDNA合成过程。
“Twist的MGF在这里帮助您以较少的工作实现更多成果”
历史上,为了可靠地生产大量的混合DNA片段,制造商不得不将片段大小缩减到仅150至300个碱基对的长度。这意味着,对于大多数应用,研究人员必须将多个DNA片段拼接在一起以创建他们所需的序列,无论是基因、抗体可变区还是串联指导RNA。这样做增加了复杂性和资源限制,可能会限制筛选项目的规模、效率和影响力。
简而言之,创造混合合成DNA片段的局限性迫使研究人员在实验设置期间做更多工作,以获得不理想的回报。这就是Twist的多重基因片段(MGF)可以帮助的地方。通过MGF,Twist现在提供使用直接合成制作的301至500个碱基对长度的混合定制双链DNA片段,几乎具有无限的扩展潜力。通过在多重dsDNA合成中增加长度和规模,MGF代表该领域向前迈出了重要一步。
推动DNA合成的边界
MGF提供的额外好处为研究人员开辟了新的和重要的可能。最令人兴奋的应用之一在于抗体的发现和开发。抗体因其独特的与特定抗原结合的能力,在治疗和诊断设置中至关重要。抗体工程的一个关键焦点领域是优化互补决定区(CDRs),其中氨基酸序列的细微变化可以显著改变表位结合动力学。
💻 人工智能/机器学习在抗体开发中的力量
AI和ML已经开始转变各种科学领域,抗体开发也不例外。通过分析大量数据集,这些技术可以识别模式并预测哪些抗体序列最有可能成功。AI/ML驱动的库比传统库小得多,后者通常包含数百万种变体。相反,这些更智能的库可能只包括数千种变体,每种都经过仔细选择以期潜在效力。
要了解Twist的MGF如何支持抗体开发,请阅读华盛顿大学Baker实验室最近的预印本:原子级精确的单域抗体全新设计。
传统上,抗体的发现和优化涉及创建广泛的变体库进行大规模筛选。为此,通过合成并以各种组合连接短DNA片段来组装库。虽然这种方法有效,但它引入了一种随机性,阻止了对创建哪些变体以及以什么数量的完美控制。
这种缺乏控制在优化过程中尤其具有破坏性,此时研究人员已经确定了候选抗体,希望通过对CDR序列进行合理变更来精炼候选属性。借助人工智能(AI)和机器学习(ML)软件,这些库的设计越来越精细,使研究人员能够缩小筛选范围至一个富集的候选池。然而,使用传统的库合成方法,创建一个定义狭窄的池是一个挑战性任务,并且存在变体表示不足的风险。
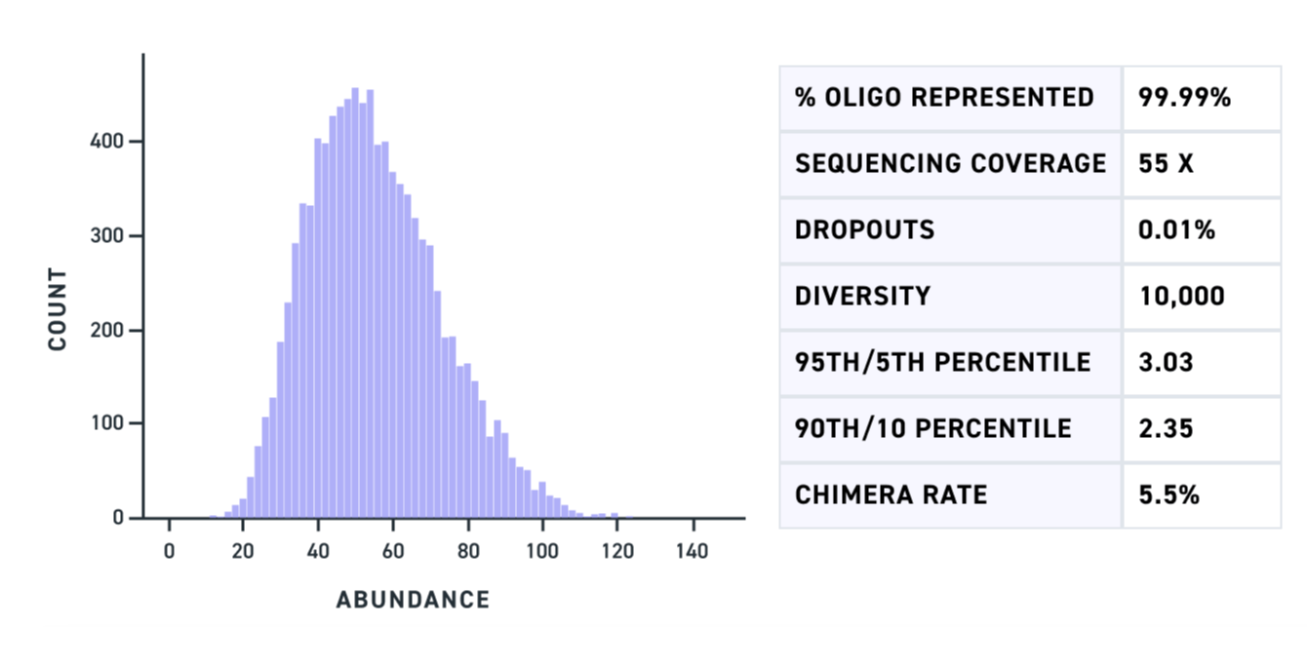
幸运的是,抗体可变区域——CDR所在的位置——大约400-450 bp长。通过直接合成长达500 bp的片段,MGF使研究人员能够编码整个抗体可变区域,包括所有三个CDR,在一个单一片段中。这种控制级别允许高度精确地设计和合成抗体变体库。Twist的MGF池实现了每个订购序列的全面表示,确保对变体构建的精确控制,从而实现更有针对性的理性筛选(图1)。而且,通过高分辨率控制CDR序列,研究人员可以将他们的筛选池大小减少到匹配AI/ML设计,最终开启更高效和有成效的筛选之门。
扩大筛选视野
MGF的优势不仅限于抗体开发。参与mRNA筛选和大规模并行报告基因分析的研究人员也可以获得显著的好处。mRNA筛选通常需要研究非编码调控元件——如未翻译区域(UTRs)——这可能影响mRNA动态。重要的是,UTRs经常超过200个碱基对。有了MGF,合成这些DNA筛选池变得简单,便于更多地控制试验设计,并且像抗体优化一样,实现高效的研究。
此外,MGF在CRISPR技术领域开辟了新的道路。
CRISPR是一种强大的基因编辑工具,它依赖于导向RNA,这些导向RNA将Cas酶定位到特定的DNA或RNA序列上。近年来,对更长的DNA片段的需求稳步增长(参见我们对不断变化的CRISPR景观的深入探讨)。研究人员可能希望在一个单独的载体中编码多个导向RNA,每个都针对同一个基因以增加敲除效率。或者,可以使用多个导向同时干扰不同的基因,揭示潜在的上位关系和合成致死组合。其他研究者则对CRISPR技术的更高级应用感兴趣,以执行PRIME编辑,其中内源序列被一个合成设计且通常较长的DNA序列替换。
在每种使用案例中,确保精确合成CRISPR载体(携带导向RNA、模板DNA、报告基因或其他元素)是至关重要的。即使是单个碱基的错误也会减少基因组编辑的成功并导致错误的结论。MGF能够以池化格式生产更长的DNA片段,同时保持高准确性和均匀性(图1),允许在单个500bp片段内包含多个导向RNA(4-6)。结果是在先进的CRISPR筛选应用中具有更高的精度和潜力,从多导向传递到PRIME编辑。 挑战与价值的规模
内部组装是一个传统的实验室过程,几十年来使研究人员能够拼凑出定制的DNA序列。然而,当研究需要大量的片段库时,这个过程可能会很麻烦且成本高昂。这意味着对于大多数实验室来说,创建数千到数百万深度的库可能是不可能实现的,如果不是不切实际的话。
Twist的MGF通过减少片段组装的需要帮助缓解这一痛点,提供看似无止境规模的长DNA片段。Twist的DNA合成平台使得能够快速合成成千上万到数十万个池化的基因片段,具有工业产能,这意味着可以包括在高通量筛选中的基因片段数量没有限制,由MGF启用的应用似乎无穷无尽。 实际影响和未来前景 Twist的多重基因片段的引入是分子生物学领域向前迈出的重要一步。通过使直接合成长达500bp的池化dsDNA片段成为可能,且具有高精度,Twist的MGF简化了复杂的工作流程并减少了昂贵的错误可能性。研究人员现在可以将重点放在他们工作的创造性和创新方面,而不是被技术限制和低效率所困扰。随着科学界继续探索MGF的潜力,这种新工具的应用很可能会扩大,推动进一步的创新和发现。
设计涉及内部组装的复杂实验是诱人的。而且这是可行的。但每个增加的步骤都伴随着成本,无论是时间、资源还是出错的可能性。在这种情况下,做得更多可能会有递减的回报。Twist的MGF在这里帮助您做得更少而成就更多。
原英文链接:https://www.twistbioscience.com/cn/blog/science/Multiplex-Gene-Fragments
推荐文章
-
 Twist推出的多基因片段库(Multiplexed Gene Fragments)首次突破300 bp的传统合成极限,实现500 bp长片段的高通量合成。
Twist推出的多基因片段库(Multiplexed Gene Fragments)首次突破300 bp的传统合成极限,实现500 bp长片段的高通量合成。 -
 低起始量样本的靶向甲基化测序通常存在相当大的挑战,因为未甲基化胞嘧啶的转化降低了基因组测序的复杂度。Twist 的甲基化检测系统通过组合探针的能力(可以实现不同级别的优化过滤严谨度)有效地克服了这些障碍,同时还引入了甲基化促进剂,这是一种定制的阻断剂,通过减少脱靶来产生协同作用,以提高系统性能。这两种优化都极大地提高了甲基化检测组合观测到的测序性能,促进了 Twist 甲基化检测系统可支持液体活检等高灵敏度应用的改进。...
低起始量样本的靶向甲基化测序通常存在相当大的挑战,因为未甲基化胞嘧啶的转化降低了基因组测序的复杂度。Twist 的甲基化检测系统通过组合探针的能力(可以实现不同级别的优化过滤严谨度)有效地克服了这些障碍,同时还引入了甲基化促进剂,这是一种定制的阻断剂,通过减少脱靶来产生协同作用,以提高系统性能。这两种优化都极大地提高了甲基化检测组合观测到的测序性能,促进了 Twist 甲基化检测系统可支持液体活检等高灵敏度应用的改进。... -
 专家视角|Julian Jude谈功能基因组学的新时代 市场部 Twist Bioscience 拓唯思特 2025年02月18日 17:30 北京 当下正是功能基因组学研究的黄金时代。CRISPR技术工具库的持续扩展,使研究者能以更复杂、更大规模的方式操控基因组;人工智能(AI)助力多模态数据分析,不仅能优化功能筛选设计,还能从中挖掘更深层的生物学意义。如今,功能基因组学研究已迈入规模化与高效化并行的新纪元。这些划时代的进步,离不开合成DNA制备技术的同步革新——这一常被忽视的技术,实为现代分子生物学的基石。 近期,我们与Julian Jude博士 深入探讨了过去十年合成DNA技术的演进,以及它如何推动当今功能基因组学的蓬勃发展。 专家简介 Julian是功能基因组学领域的资深专家,拥有20余篇学术论文及多项专利申请。在攻读博士及博士后期间,他开发了用于靶点识别的新型功能基因组学工具,主导了70余项全基因组shRNA与CRISPR筛选项目,并参与创建了CRISPR单导RNA(sgRNA)设计评分...
专家视角|Julian Jude谈功能基因组学的新时代 市场部 Twist Bioscience 拓唯思特 2025年02月18日 17:30 北京 当下正是功能基因组学研究的黄金时代。CRISPR技术工具库的持续扩展,使研究者能以更复杂、更大规模的方式操控基因组;人工智能(AI)助力多模态数据分析,不仅能优化功能筛选设计,还能从中挖掘更深层的生物学意义。如今,功能基因组学研究已迈入规模化与高效化并行的新纪元。这些划时代的进步,离不开合成DNA制备技术的同步革新——这一常被忽视的技术,实为现代分子生物学的基石。 近期,我们与Julian Jude博士 深入探讨了过去十年合成DNA技术的演进,以及它如何推动当今功能基因组学的蓬勃发展。 专家简介 Julian是功能基因组学领域的资深专家,拥有20余篇学术论文及多项专利申请。在攻读博士及博士后期间,他开发了用于靶点识别的新型功能基因组学工具,主导了70余项全基因组shRNA与CRISPR筛选项目,并参与创建了CRISPR单导RNA(sgRNA)设计评分...